Event Sourcing - Greg Young - GOTO 2014 {youtube}
Scraps
이벤트 소싱은 개념적으로 은행, 보험, 도박, 금융같은 모든 곳에서 자연스럽게 사용되어왔습니다.
비즈니스와 이벤트 소싱은 함께가는 것이다.
All state in you system is a first level derivative off of your facts.
이벤트 소싱이란, 오직 사실만을 적시한 것을 의미합니다. 시스템의 상태는 오직 팩트로부터 파생됩니다.
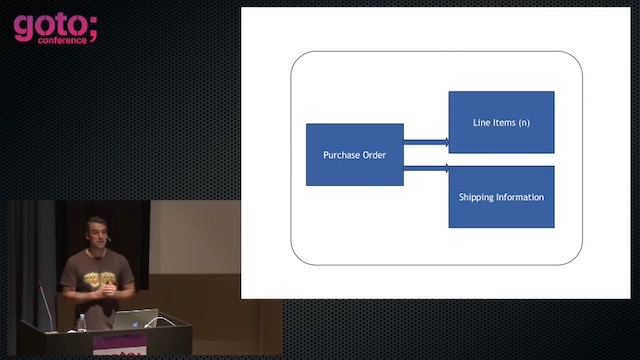
이 다이어그램은 우리가 전통적으로 사용하는 데이터 모델

세가지 Distinctable한 이벤트만 있으면 전통적인 데이터모델을 흉내낼 수 있음. 어떻게 하냐고? 리플레이를 하면 된다. 여기서 중요한 말이 나오는데,
An Event Source system is that all state is transient. Don't get me wrong, it can be persistent but it is transient.
transient | ˈtran(t)SHənt, ˈtranZHənt |
adjective
lasting only for a short time; impermanent: a transient
이벤트 소싱에서 업데이트 또는 삭제는 일어나지 않습니다. 연필은 쓰지 않습니다. 오직 펜만 씁니다.
Partial Reversal? Full Reversal?
내가 1000원을 이체해야 하는데 실수로 10000원을 이체해버린 경우, 두가지 옵션이 있다:
- 9000원만 돌려주기 → partial reversal
- 10000원을 돌려주고 다시 1000원을 이체하기 → full reversal
partial reversal은 의도를 파악하기가 어렵다. 이것이 만약 rounded number였다면? 부분취소 이후 금액에 변동이 생길수도 있다. 그래서 회계업계에서는 full reversal을 선호한다고 한다. 10000원을 다시 돌려주고 취소 태그를 달아 이것이 의도된 것임을 남긴다.
의도를 남기는 것이 중요한 이유는 이 로그를 나만 보는 것이 아니기 때문이다. 감사원이 볼 수도 있고, 다른 개발자가 볼 수도 있고, 회계원이 볼 수도 있기 때문이다.
When we talk about Event Source systems we tend to prefer full reversals as opposed to partials.

이런 이벤트 흐름이 있다고 하자. 카트에 3개의 아이템을 추가하고 1개의 아이템을 제거한 다음 결제했다. 이 경우 단순히 2개의 아이템을 카트에 넣어 결제한것과 동일할까?
It Depends
결과론적으로 봤을땐 완전히 동일하고 전통적인 데이터베이스 구조에 따르면 차이를 알 수 없다. 하지만 다른 관점에서 "얼마나 많은 아이템이 삭제가 되었는지"에 대한 정보는 소실되어버렸다. 소실된 자료가 당신에게 얼마나 중요한지에 따라 이것을 이벤트 스트림으로 저장할 건지, 전통적인 데이터베이스 구조를 사용할건지 결정할 중요한 요인이 된다.
Conceptually event sourcing does not lose information
사실 이벤트 소싱을 구현하는 방법은 정말 다양하다. 수기로 할 수도 있고, SQL 데이터베이스에 Descriptor 테이블을 추가하여 엔티티 상태변화의 히스토리를 쌓을 수도 있다. 그냥 사실만 적으면 된다.
When we talk about deriving state off of an event stream it's known as a Projection
"장바구니에 아이템을 삭제한지 5분 이내에 결제한 유저는 나중에 높은 확률로 그 아이템을 다시 살 겁니다" 라는 예상을 증명하기 위해선 비즈니스 리포트를 출력할 수 있어야 한다. 이벤트 소싱에서는 이벤트 스트림을 left-fold, reduce 하여 아이템이 삭제된 시간과 결제가 이루어진 시간을 직접 비교해볼 수 있게된다.
- 장바구니에서 삭제된 이력이 있는 아이템을 찾는다. 이 아이템이 삭제된 시간을 메모리에 저장한다.
- 결제가 이루어진 시간을 아이템이 삭제된 시간과 비교하여 5분 이내의 건들만 추린다.
- 자 이제 이 아이템들이 재구매가 이루어졌는지 여부를 찾는다.
- Profit 💵
Event sourcing system stores event stream Sequentially and you can become very very fast
은행에서 대출 앱을 개발한다고 가정할때, 하나의 라이프사이클(상품조회, 비교, 계약서 확인, 계약체결 등등)을 위해 대략 몇개 정도의 이벤트가 필요로 할까요? 약 50건 정도가 필요합니다.
구글에서 하루에 대략 몇개 정도의 이벤트가 발생할까요? 못해도 적어도 백만건은 될 겁니다.
전체 시스템에 쌓이는 이벤트에 비해서 하나의 라이프사이클 안에서 이벤트가 쌓이는 속도는 상대적으로 매우 느립니다. 하루가 걸릴 수도 있고 일주일이 걸릴 수도 있죠.
Avoid snapshots if you can
구글같이 이벤트가 몇백만개씩 쌓이는 경우가 아니고서야 스냅샷은 버저닝이 매우 어렵고 동시성 문제가 발생할 확률이 높다.
You don't query your events, you end up with a concept known as Read Models
잘못된 읽기모델을 구현하면 우발적인 복잡성이 높아질 수 있다.
트위터 초창기에는 토픽 기반의 pub-sub 모델을 사용했다. 이름, 해시태그가 있고 사람들은 그 토픽에 구독하여 스레드를 이어갈 수 있었다. 하지만 그 모델을 구현하기 위해 수백개의 MySQL 인스턴스를 사용하였으나, 결과는 좋지 못했다.
The consumer remembers where they are in the event stream, not the producer
CQRS was never really intended to be much of a pattern
When we talk about migrating existing data over to an event source system, there are two ways of actually dealing with it
- 회계 시스템과 똑같이 하라. 모든 트랜잭션 로그들을 실행하거나
- 레거시 애그리거트와 모던 애그리거트를 구분하라. 레거시 애그리거트는 일종의 스냅샷의 형태가 된다. "Aggregate by Aggregate"
또는 두 전략을 같이 사용하는 방법이 있다.
2025-07-25 모든 걸 요약한 댓글
00:00 Introduction (it is not a new idea)
01:00 What brought them towards Event Sourcing
01:25 Mature businesses like finance, banking, gambling, insurance are all naturally event sourced
03:00 Definition of event sourcing - all state is transient, only store facts
06:46 We never update or delete facts in event sourced systems
11:52 Event Sourcing is the only model that you can possibly use that does not loose information
14:05 Projections - Deriving state off of an event stream
15:04 Projections must start at event 0
16:16 Projections can be done for every point in time since the start of the system
17:09 "You can not change what happened in the past, but you can have a new perception of what happened in the past"
17:39 Advantages of event sourcing from a developers point of view
17:52 It's sequential writing -> fast (~50.000-100.000 requests per sec on a fairly naive system on one node)
18:39 Go back in the past
19:19 Easy smoke tests (for me he even describes full regression tests not just smoke tests)
20:16 Prevent super user attacks
24:45 Snapshots
26:42 Store snapshots off the side and point back to the version of the event log
27:11 You can also have multiple different folds with different perception of the same version of the event log in parallel
27:26 Avoid snapshots if you can (state is hard to version)
29:53 How do I query a series of events? You don't. You use read models .
36:22 Consider a graph database for read models
37:36 You can have as many read models as you want - they just have to subscribe to your event system
Wrong statements you hear about event sourcing:
38:01 Event sourcing needs a service bus
39:12 Problem: if you want to add a new read model you need to replay the former events. With a service bus you would need an additional control channel to ask for events.
Use a consumer driven subscription system like Kafka
41:55 Event sourcing is more complex (than CRUD systems)
It seems more complex to people that are used to the CRUD way just because it's another way of dealing with the domain and have to learn it.
42:55 What big companies are using Event Sourcing?
Don't decide what to use because of other companies.
43:29 Event sourced systems must be slow
They can be really fast and it's used for latency sensitive systems eg for trading
44:25 Event Sourced systems must be object oriented
No, it is an inherently functional system. You have an immutable series of events and "left fold" your state out of this series
45:12 What is the "bestest" Event Sourcing framework ever?
Probably none.
45:51 But what about all my data? With Event Sourcing it must be huge!
Don't think about the amount of data you are going to have but at which current and which future rate you will be retaining data and compare that to moore's law.
If you are slower than moore's law ( < ~5.000 req/sec) your data will get cheaper over time.
47:40 CQRS is just a teaching pattern
"CQRS is the dumbest pattern ever written". It was never meant to be a pattern. The main idea is to make people see the benefits of separating the reading and the writing part of the process.
49:34 Event Sourcing is not 'enterprisy'
True, thanks.
Questions
50:33 How to know what details to put in an event?
That's an use case analysis problem
51:59 How to avoid the big bang release when switching to event sourcing?
Two ways of dealing with migrating data to an event sourced system
- Either migrate all data and transactions of all accounts to the new system
- or just bring in the initial balance
Decide which one to use aggregate by aggregate. Either you can reverse engineer the history or save a snapshot as init-event.
This allows to run the systems side by side. The old system can already raise the events